0%
经典的探索策略
Epsilon-greedy 探索策略。这种方法是最经典的,在 DQN 系列的算法经常被使用。
置信区间上限UCB。每一个选择对应一个乐观的index(回报的经验均值+confidence radius),智能体会选择index最大的动作。
- 公式第一项可以看成是利用
- 公式第二项就是探索,与该动作的被探索程度成正比
Boltzmann 探索。智能体根据由温度系数调节的 Q 值从玻尔兹曼分布 (softmax)中选择动作 \(a\)。表达式如下:\(\pi(a \mid s)=\frac{\exp (k Q(s, a))}{\Sigma_{a^{\prime}} \exp \left(k Q\left(s, a^{\prime}\right)\right)}\)
当神经网络用于函数逼近时,采用以下的探索策略
- 策略熵。将熵项加入到损失函数中,鼓励策略采取多种行动;
- 基于噪声的探索。噪声可以加到观测、动作甚至的参数空间中去。
前提条件
- 尽可能多掌握英语单词,做到少用或者不用英语翻译软件就可以阅读文献;
- 对该领域存在好奇心;
- 对自己有信心。
方法步骤
- 拿到一篇文献,先阅读该文献的摘要、结论部分,确定一下这一篇文献你是否需要;
- 如果这篇文献适合你,那么接下来从Introduction部分开始阅读;
- 每读完每一小结之后,自己可以稍微总结一下本节的重点内容,注意逻辑方面的联系。可以边读文献边不断地自己问题,带着问题读文献的效果很好;
- 这篇文章的出发点是什么?
- 用到的方法是什么?
- 之前有人做过这个没,作者又是怎么做的,有什么不同之处?
- 你觉得方法亮点是什么?
- 对这篇文献的评价,优缺点?
- 最后,读完了这篇文献,再结合之前记的笔记,从整体上对笔记进行补充。并对好的语句进行摘抄,收录到自己的写作库中去。
注意事项
- 带着批判性眼光去看待作者所提出来的观点。作者所说的不一定是对的,要有质疑精神;
- 对于方法不一定要搞得很懂,除非这篇文章的方法你可能会借鉴。
- RL机器人问题,是连续高维动作和状态空间
- RL机器人控制三个方面问题:
- 数据效率低
- 提高数据效率的方法之一是收集更多的数据和更有效地使用目前拥有的数据
- 收集更多数据的方法之一是并行地运行多个机器人来收集数据
- 探索与利用
- 真实机器人进行探索,可能会损伤机器人
- 同策略方法中探索性取决于初始的条件和训练过程。在训练策略的过程,可能会注重于利用
- 泛化性和可复现性
- 当前的某些算法只注重于某一种任务,而到了另一种任务的时候需要重新调节参数
- 随机种子数影响着能否复现成功
- 策略梯度如下式:
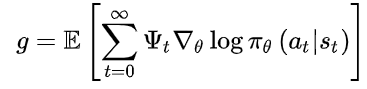
- 其中, \(\pi_{\theta}(a \mid s)\) 为Actor, \(\Psi_{t}\) 称为Critic,此式是一个广义的AC框架。
- \(\Psi_{t}\) 可以取以下几种:
- 轨迹总回报,\(\Sigma_{t=0}^{\infty} r_{t}\)
- 执行动作后的回报,\(\Sigma_{t^{\prime}=t}^{\infty} \boldsymbol{r}_{t^{\prime}}\)
- 加入基线的形式,\(\sum_{t^{\prime}=t}^{\infty} r_{t^{\prime}}-b\left(s_{t}\right)\)
- 状态-行为值函数,\(Q^{\pi}\left(s_{t}, a_{t}\right)\)
- 优势函数,\(A^{\pi}\left(s_{t}, a_{t}\right)\)
- TD-error,\(r_{t}+V^{\pi}\left(s_{t+1}\right)-V^{\pi}\left(s_{t}\right)\)
- 前三个critic直接利用轨迹的累积回报,由此计算出来的策略不存在偏差,但是由于是多步的累积回报,因此方差很大
- 后三个利用动作值函数,优势函数和TD偏差来代替累积回报,因而方差下,但是由于这三种方法都用到了逼近,因此计算出来的策略梯度存在偏差。当critic取后三个时,为经典的AC算法。

A2C算法
- A2C使用优势函数代替Critic网络中的原始回报,可以作为衡量选取动作值和所有动作平均值好坏的指标。
- 优势函数:
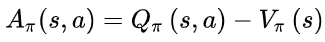
- 意义:如果优势函数大于0,则说明该动作比平均动作好,如果优势函数小于0,则说明当前动作还不如平均动作好
- 理解:如果优势函数大于0 ,那么Q>V,V在里面可以表示一个平均动作下的价值
A3C算法
- 异步优势动作评价算法,存在多个并行环境来收集数据,打破数据之间的关联性。